近日,百度在海外官方账号介绍了最新轻量级文字识别模型 PP-OCRv5。该模型仅0.07B参数,以千分之一参数量实现与700亿参数大模型相媲美的OCR精度。在多项 OCR 场景测试中,PP-OCRv5 的表现超越GPT-4o、Qwen2.5-VL-72B等通用视觉大模型。最新信息显示,飞桨团队发布的技术Blog已连续一周登顶Hugging Face博客热度榜首,受到开发者社区的广泛关注。 <a href=\"#\" rel=\"nofollow\"> 据了解,2025年5月,飞桨团队推出PaddleOCR 3.0版本,文字识别方案PP-OCRv5与通用文档解析方案PP-StructureV3,以及原生支持文心大模型4.5的智能文档理解方案PP-ChatOCRv4共同构成其三大特色能力。自2020年开源以来,PaddleOCR累计下载量突破900万,被超过5.9k开源项目直接或间接使用,是GitHub 社区中唯一一个 Star数超过50k的中国OCR项目。 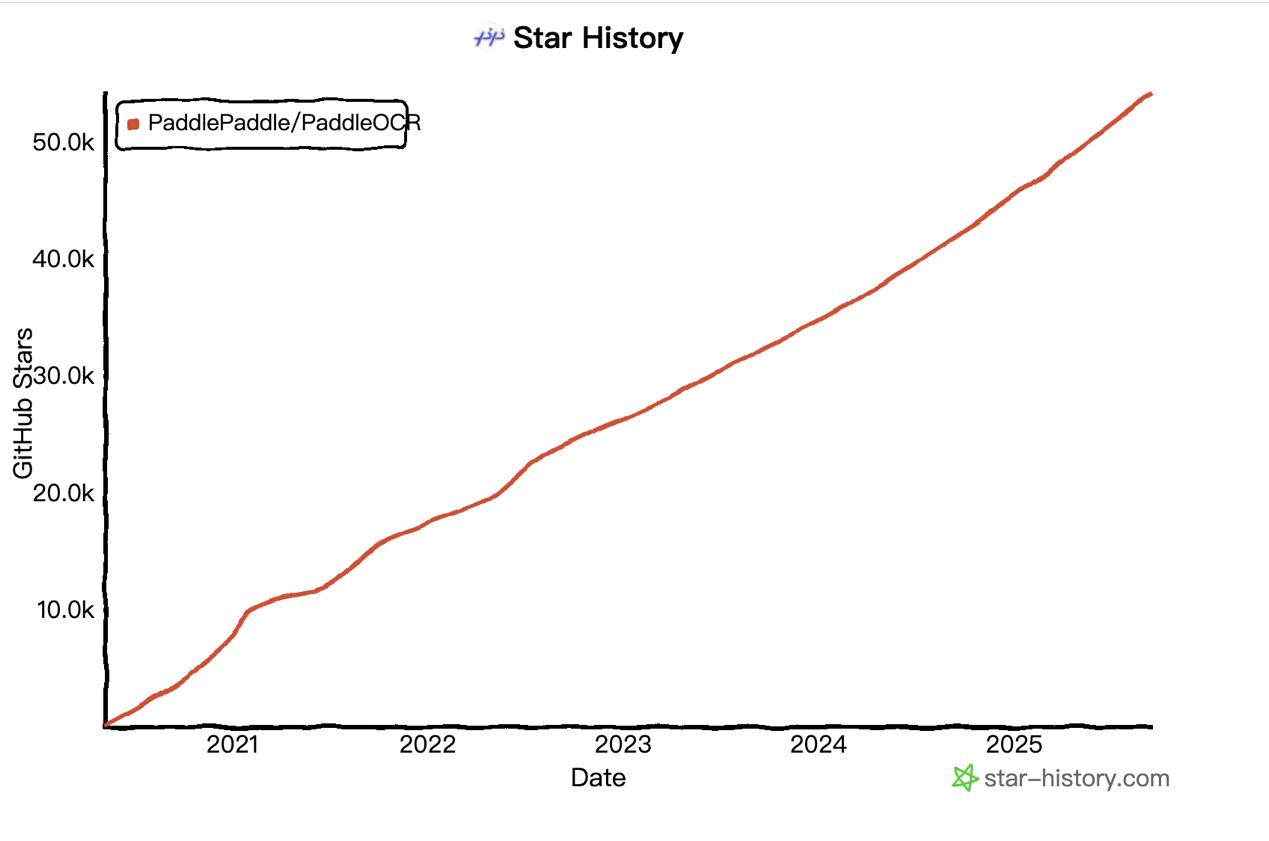 <a href=\"#\" rel=\"nofollow\"> 9月18日晚,Paddle OCR项目登上了GitHub全球总榜 trending榜, 位于python榜第5,总榜第13。 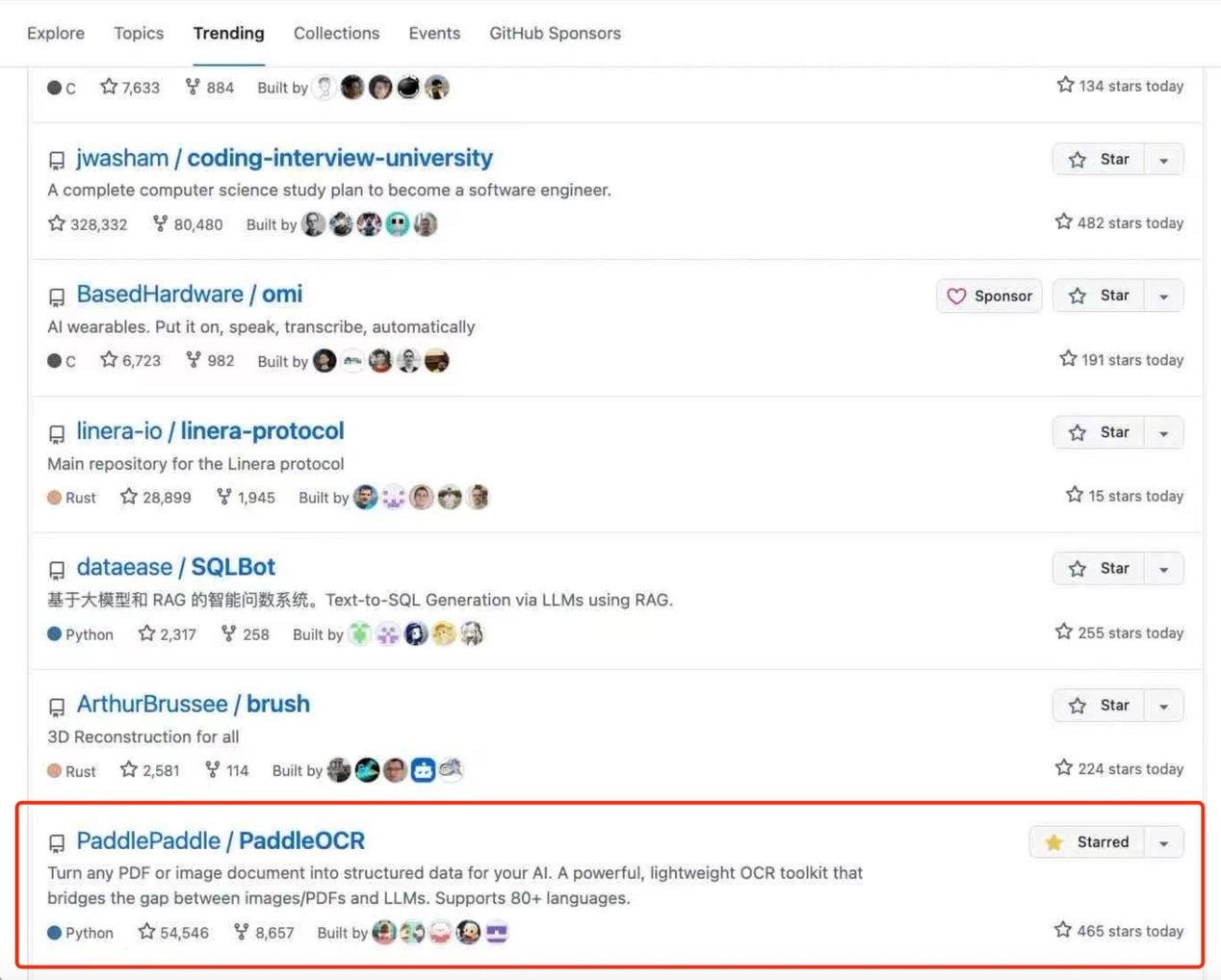 <a href=\"#\" rel=\"nofollow\"> Blog指出,在OCR场景中,通用视觉大模型(VLM)在精确文本定位和边框精度上仍面临挑战,同时容易带来高计算开销和“幻觉”输出。相较于VLM,PP-OCRv5采用了模块化双阶段检测与识别方案,能够实现轻量高效推理与更精准的文本边界框输出。 Benchmark数据显示,PP-OCRv5在 Printed Chinese、Printed English、Handwritten English 等核心任务上与百亿级大模型 Qwen2.5-VL-72B 精度持平甚至更优;在Handwritten Chinese、Chinese Pinyin等复杂场景中,仍稳居前列,表现出强泛化能力。 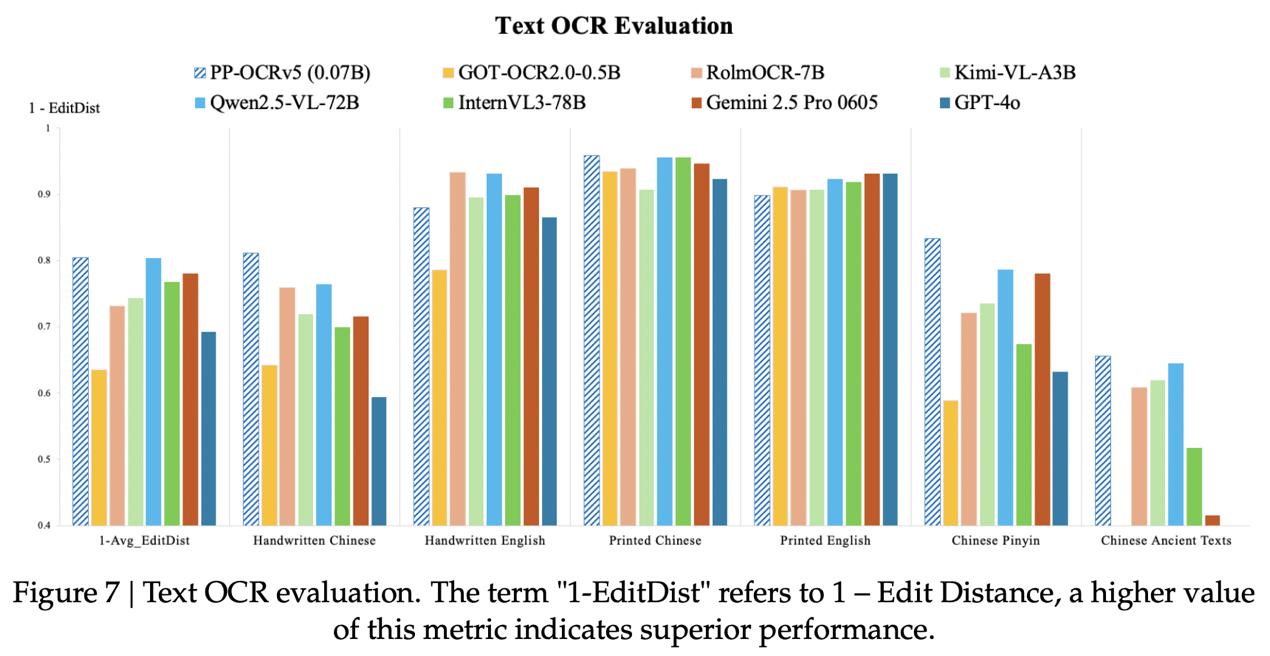 <a href=\"#\" rel=\"nofollow\"> 作为百度飞桨团队推出的全场景文字识别模型,PP-OCRv5是业界首个单模型支持5 种文字类型的超轻量级(<100M)开源模型,且支持复杂手写体识别,可广泛应用于教育行业的试卷作业批改、医疗行业的病历数字化、法律行业的合同笔录数字化等多场景业务需求。 『本文转载自网络,版权归原作者所有,如有侵权请联系删除』 |
 /1
/1 


关于我们|手机版|EDA365电子论坛网 ( 粤ICP备18020198号-1 )
GMT+8, 2025-9-23 18:45 , Processed in 0.140625 second(s), 28 queries , Gzip On.
地址:深圳市南山区科技生态园2栋A座805 电话:19926409050